

Whether for functional need, budgetary alignment, or due to top-down pressure, all universities will move to the public cloud at some level. If an organization has less than, say, 50 terabytes of data to manage, it’s easy to move everything there. For those of you in this boat, you can stop reading this article and proceed directly to the cloud, and collect $200.
For those with hundreds of terabytes, even petabytes, of data – including most universities – this is challenging and unrealistic. The business value of public cloud infrastructure is desirable, but when there are such large volumes of data, it’s hard to get there. “Lift and shift” strategies to mimic on-site infrastructure in the cloud are not often viable when petabytes of data are involved, and many universities need to keep at least some data on the premises. Luckily the utilization of public and private infrastructure does not have to be an either/or decision.

Fortunately, you can realize many of the business benefits of the public cloud in your own data centers. Elimination of silos, data that’s globally accessible, and pay-as-you-grow pricing models are all possible on-premises, behind your firewall. The “hybrid cloud” approach is not simply having some apps running in your data center and other apps running in Amazon or Google. Workflows do not have to wholly reside within either private or public infrastructure – a single workflow can take advantage of both. True hybrid cloud is when public and private resources can be utilized whenever it’s best for the application or process.
Here are four key steps to accelerate your journey to the cloud:
Step 1: Go Cloud-Native
Storage is the primary inhibitor preventing movement towards the public cloud and cloud architectures in general. Data is siloed – stuck in separate repositories – and locked down by specific access methods required by specific applications. This makes it impossible, or at least extremely expensive, to effectively manage, protect, share, or analyze data.
“Classic” applications use older protocols to access data, while newer cloud-native applications use unique interfaces. Converting everything to cloud-native format will save much time, money, and headache in the long run. This does not have to be a massive project; you can start small and progress over time to phase out last generation’s technology.

Once you’re cloud-native, not only is your data ready to take advantage of public cloud resources, but you immediately start seeing benefits in your own environment.
Step 2: Go According to Policy

On-premises data on cloud-native storage can be easily replicated to the public cloud in a format all your applications and users can work with. But remember, we’re talking about hundreds of terabytes or more, with each data set having different value and usability.
Data management policies in the form of rules help decide where data should be placed based on the applications and users that need it – parts of your workflow behind your firewall and other parts in the public cloud. For example, you may be working with hundreds of terabytes of video, but would like to take advantage of the massive, on-demand processing resources in Google Cloud Platform for transcoding jobs instead of local hardware. Set a policy in your cloud storage software to replicate that on-prem video to the public cloud, then let Google do all the work, and set a policy that says move the transcoded assets back down when complete for the next step in the flow.
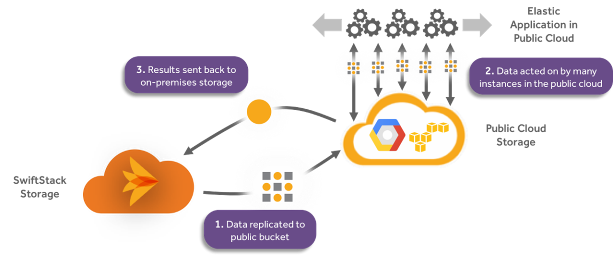
Don’t worry – the cloud data management software “views” the entire infrastructure as a single pool, universally accessible, regardless of the kind of storage or location.
(Next page: Steps 3-4)
Step 3: Go Cloud to Cloud
Policies help automate and orchestrate services to your applications based on business requirements (e.g. cost, capacity, performance, and security), according to the different capabilities of your on-premise or cloud resources. This also means data is efficiently discoverable and accessible across multiple clouds – the cloud data management platform considers the differences in services provided by the different clouds and moves or copies data to the right one.

When data is organized by storage silo or tracked by databases that only a single application has access to, the data can most often only be utilized that single application or a small number of users. Instead start to use metadata as the organizing principle for your data, which is enabled by cloud-native storage. When metadata sits right alongside the data it’s representing, it can be globally indexed and made available to many applications and groups of users.
Step 4: Go Deep
When data placement policies enable a true hybrid cloud workflow, not constrained by physical infrastructure, you can unlock more capabilities. You can start to use metadata – the data about the data – as what we call the organizing principle. Cloud-native data holds its own metadata right alongside it, not in a separate database only its own specific application can read. Your metadata can now be globally indexed and made available to many applications and groups of users.
Whether you like it or not, you will be in the cloud in some capacity. Follow these steps to not only make the transition to public infrastructure hassle-free, but to bring many of the business dynamics of cloud – pricing based on consumption, massive scalability, collaboration, etc. – into your datacenter and increase the value of your data.

Erik Pounds is head of product marketing at SwiftStack.
- A bungled FAFSA rollout threatens students’ college ambitions - April 19, 2024
- Using real-world tools to prepare students for the workforce - April 18, 2024
- 8 top trends in higher education to watch in 2024 - April 16, 2024